Terraform at Scale: Patterns and Anti-Patterns
Only 6% of organizations have achieved full cloud codification. That means 94% of companies running Terraform are still managing significant chunks of their infrastructure by clicking around in a console. And according to the Firefly State of IaC 2025 report, 65% of respondents say cloud complexity has actually increased over the last two years, despite better tooling. Terraform is not the problem. How we use it is.
This post is about what separates teams that run Terraform smoothly at scale from those drowning in state file corruption, 45-minute plan times, and midnight pages caused by drift they did not know existed. I have spent years working with infrastructure at scale, and the patterns here come from studying how companies like Cloudflare, Stripe, Uber, and Benchling actually operate, not from vendor marketing.
The Problem with “Just Use Terraform”
Terraform holds roughly 34% of the configuration management market. The AWS provider alone has crossed 5 billion historical downloads. It is, by any measure, the dominant IaC tool.
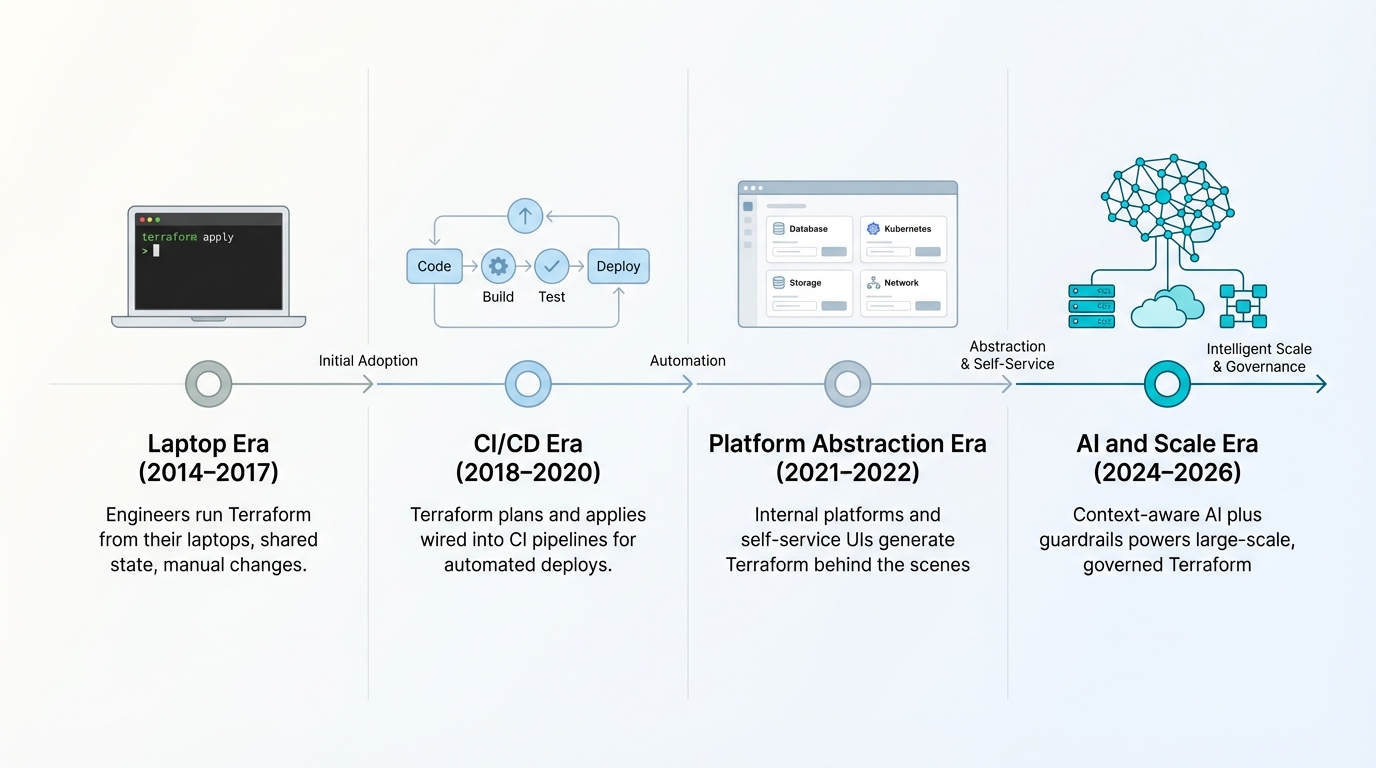
But dominance does not equal maturity. Most organizations are stuck in what I call the “laptop era” of Terraform usage: engineers running terraform apply from their machines, sharing state files over S3 with no locking, and treating modules like copy-paste templates. This worked when you had 50 resources. It falls apart at 500. It becomes actively dangerous at 5,000.
The real shift that high-performing organizations have made is treating Terraform not as a CLI tool, but as the backend execution engine of a governed, automated platform. Application developers in these environments rarely touch HCL directly. They interact with internal platforms, constrained modules, or self-service portals that generate Terraform configurations behind the scenes.
The 2024 DORA report (surveying over 39,000 technology professionals) adds an important wrinkle here. AI-assisted code generation is accelerating IaC authoring, with tools like GitHub Copilot delivering a roughly 55% productivity boost for HCL syntax generation. But the same report found that for every 25% increase in AI adoption, delivery stability drops by 7.2% and throughput decreases by 1.5%. Writing Terraform faster is not the bottleneck. Validating, testing, and safely deploying it is.
That tension, between the speed of writing infrastructure code and the ability to safely ship it, is the central challenge of running Terraform at scale.
How the Best Teams Actually Run Terraform
Kill Manual Execution First
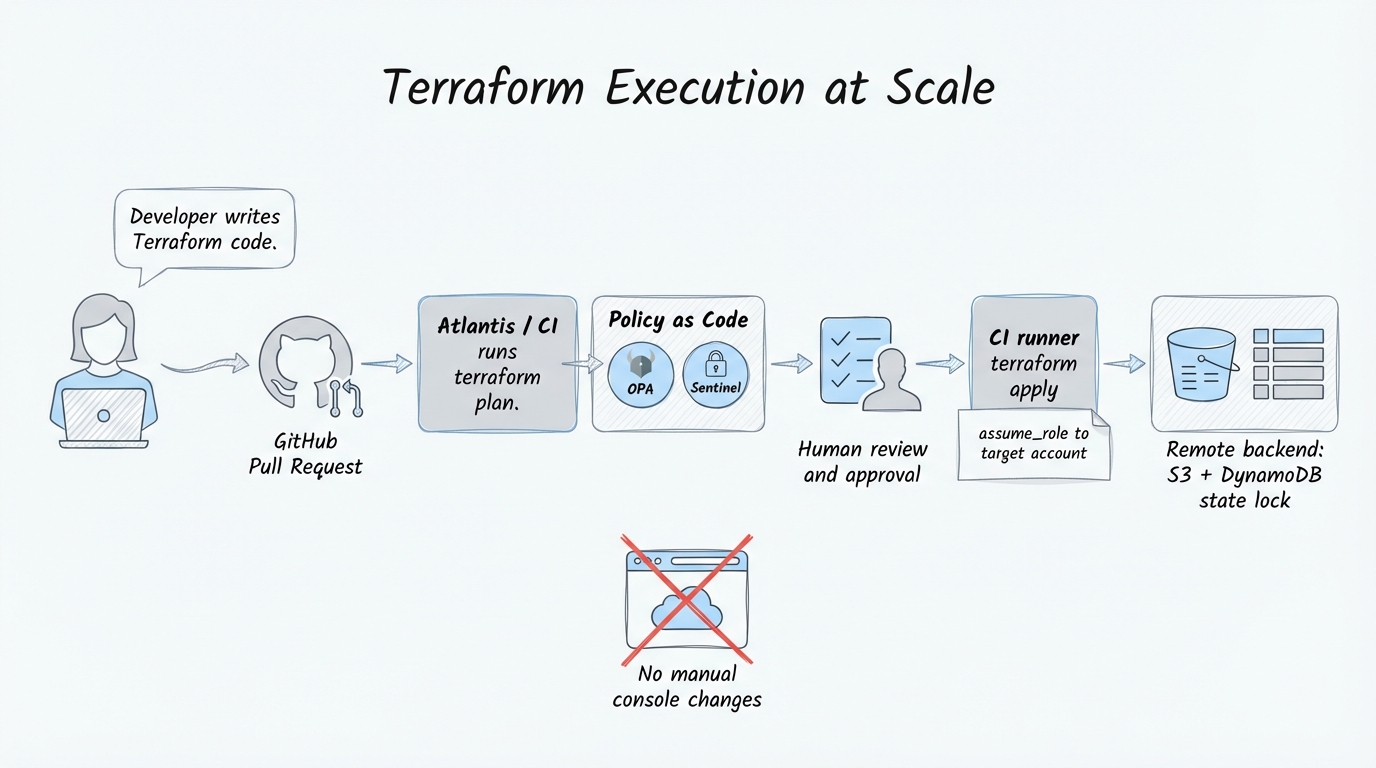
The single most impactful change you can make is banning terraform apply from developer laptops. Full stop.
Cloudflare learned this the hard way. As the company scaled to hundreds of internal accounts and dozens of products, relying on manual UI dashboard changes and individual administrator accounts led to untracked configuration drift, undocumented modifications, and security risks around API key management. Their fix was aggressive: they moved to a strict monorepo for all Terraform configurations, deployed Atlantis to tie every infrastructure change to a GitHub pull request, and built a custom Zero Trust toggle that forces the Cloudflare UI into read-only mode. No one can make manual changes outside of the codebase. Period.
The result: 100% peer-reviewed accountability for all infrastructure changes, API tokens managed via service accounts instead of individual credentials, and a daily terraform apply pipeline that catches and overwrites unauthorized drift automatically.
Benchling tells a similar story from a different angle. Their engineers were running Terraform locally and, to minimize the pain of slow execution, they crammed everything into massive monolithic workspaces (some with over 4,000 resources). The blast radius was the entire infrastructure. A single typo could lock the state for the whole company. When they migrated to HCP Terraform and broke their monolith into granular, microservice-scoped workspaces, they saved an estimated 8,000 hours of engineering time that had been wasted on manual coordination and troubleshooting.
The pattern here is clear: tooling friction drives architectural decisions. When running Terraform is painful, engineers consolidate to minimize runs. When you automate execution, you can afford to partition aggressively.
Module Design Determines Long-Term Maintainability
Here is the thing about Terraform modules: they are easy to write and incredibly hard to write well.
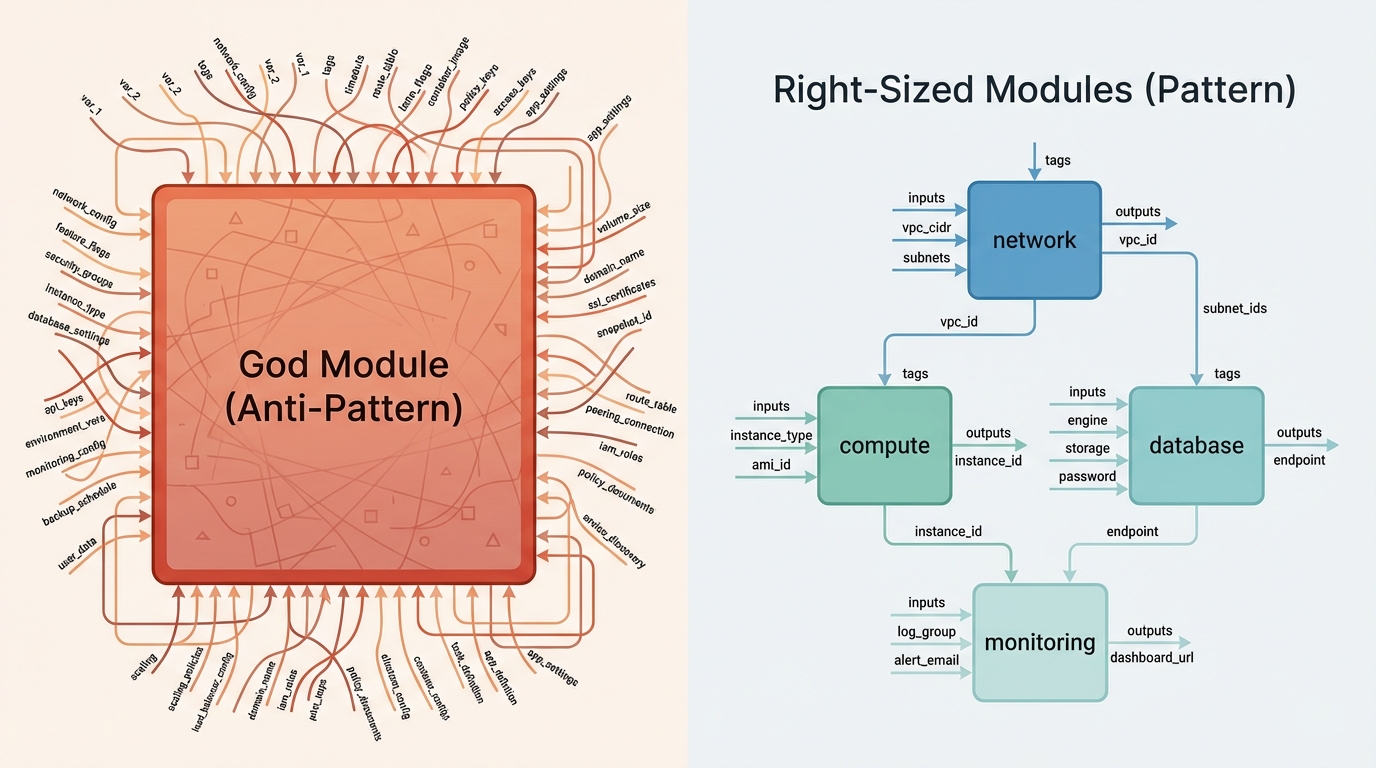
The most common failure is what I call the “God module,” a single module that tries to do everything for everyone by exposing every possible provider attribute as a variable. It starts with good intentions (DRY principles, reuse) and ends with a module that has 200 variables, is impossible to test comprehensively, and breaks downstream consumers every time you refactor.
Rene Schach, speaking at HashiDays 2025, put it well: “Every module should serve a specific purpose and audience. Modules should follow functional separation, performing one function well. A kubernetes_cluster module should only handle cluster configuration, while networking belongs in its own module.”
The second critical design principle is aligning module boundaries with resource lifecycles. Short-lived infrastructure (ephemeral dev environments, stateless compute) must never share a module with long-lived foundational components (core VPC routing, DNS zones). Mixing volatility profiles guarantees that a routine update to a dev environment will eventually trigger the accidental destruction of your core networking stack.
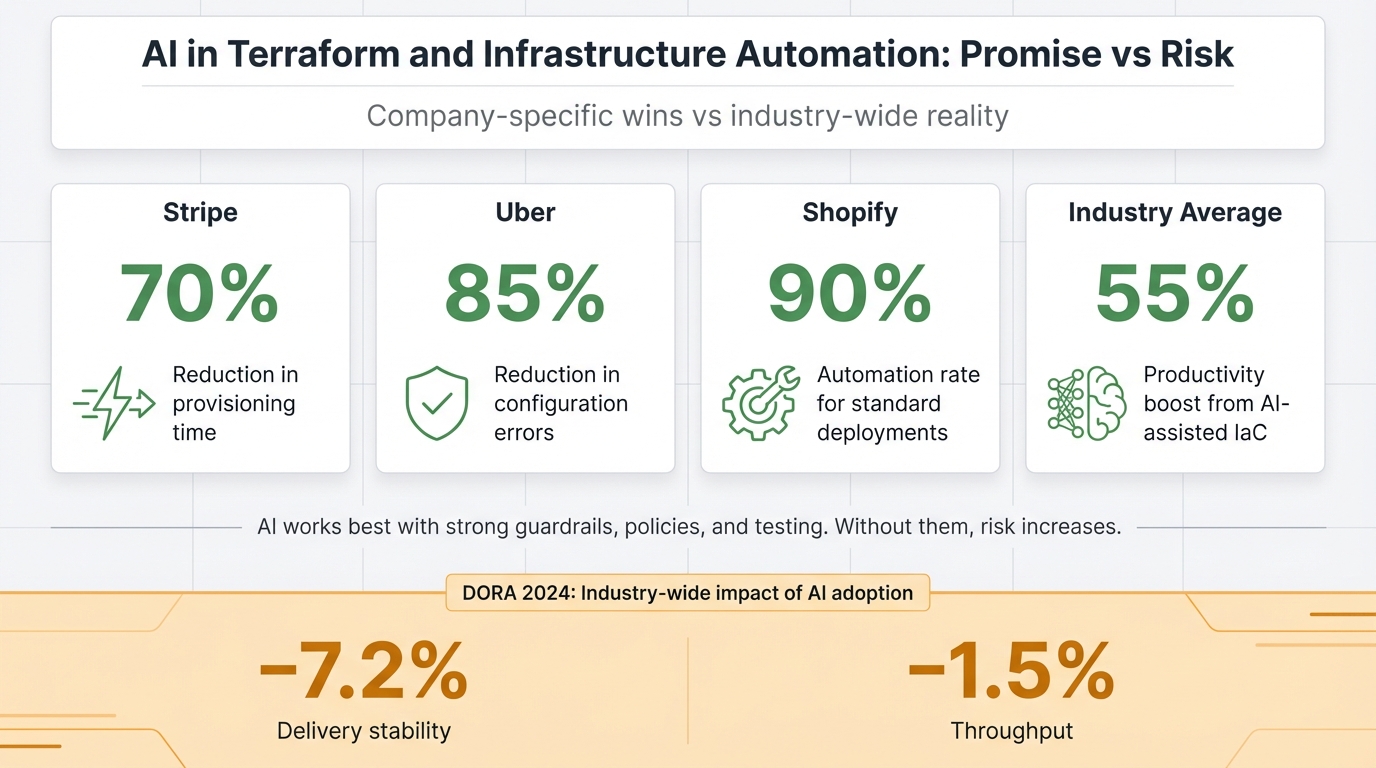
Shopify demonstrates what good module design enables at scale. They built highly abstracted modules for DNS routing and Snowflake data pipelines. Application owners can now update complex, traffic-managed domains by adjusting lightweight domain.tf files, which automatically triggers failover logic underneath. The developer does not need deep infrastructure expertise. The module encapsulates it. This, combined with a hybrid AI-human automation model (LLMs trained on company-specific patterns, with mandatory human oversight for critical infrastructure), allowed Shopify to reach a 90% automation rate for standard deployments.
Policy-as-Code is No Longer Optional
If you are running Terraform at scale without automated policy enforcement, you are one bad pull request away from a public S3 bucket or an unencrypted database.
Fannie Mae, operating in one of the most regulated environments imaginable, solved this by integrating HashiCorp Sentinel into a 5-stage Policy-as-Code pipeline. Every infrastructure policy is peer-reviewed, tested against Terraform plan mocks, and initially deployed in “advisory” mode before being promoted to “hard mandatory” enforcement. The key insight from their implementation: you must ensure backward compatibility. If you enforce new rules instantly and aggressively, you will break older infrastructure pipelines that were provisioned before the policy existed.
DoorDash took a vendor-neutral approach, coupling Terraform with Open Policy Agent (OPA) to enforce cloud-native infrastructure rules, authorization limits, and network routing constraints via a GitOps workflow on GitHub. Their CI/CD pipeline catches breaking changes, overlapping CIDR blocks, and security vulnerabilities before any code hits production.
The choice between Sentinel and OPA is less important than having something automated in the path. Manual security reviews do not scale, and relying on human vigilance for every terraform plan output is a recipe for missed misconfigurations.
AI is a Multiplier, Not a Replacement
The numbers on AI-assisted Terraform are genuinely impressive when done right. Uber deployed context-aware LLMs trained on their internal architectural patterns and compliance policies, reducing infrastructure configuration errors by 85%. Stripe built autonomous coding agents (“Minions”) that author end-to-end pull requests for infrastructure changes, cutting provisioning time by 70%. Both companies share a critical detail: the AI is tightly coupled with organizational context and strict policy guardrails.
What this actually means in practice is that generic AI (pointing ChatGPT at your Terraform codebase) produces mediocre results. Practitioners report that generic LLMs hallucinate provider attributes, create circular dependencies, and generate configurations that pass terraform validate but fail spectacularly on terraform apply. The emerging solution is grounding LLMs in your organization’s specific state files and provider schemas via Model Context Protocols (MCP).
But the DORA data should give everyone pause. The 7.2% drop in delivery stability correlated with AI adoption is not a minor footnote. As RedMonk analyst R. Stephens framed it through the Theory of Constraints: “Writing code isn’t the bottleneck to deploying reliable applications.” Generating Terraform faster via AI solves a problem that was not the actual constraint, while actively worsening the real bottlenecks of security review, state management, and integration testing.
The Pitfalls You Will Recognize
The Monolithic State File
What it looks like: One terraform.tfstate file managing your entire cloud environment. Plan times measured in minutes. A minor syntax error locks state for the whole organization.
Why it happens: Small teams start with one repo and one state file. It works. They never revisit the decision as the company grows to thousands of resources.
What to do instead: Partition aggressively into logical workspaces (core-network, app-compute, databases). Use terraform_remote_state data sources or dedicated remote outputs to pass variables between isolated states. Benchling’s 4,000-resource monoliths are the cautionary tale here.
Hardcoded Secrets and Environment IDs
What it looks like: API keys, database passwords, or exact AMI IDs sitting in .tf or .tfvars files committed to Git. Code that cannot be promoted from dev to staging to production without manual edits.
Why it happens: Setting up secure secret injection feels like overhead early on. Developers underestimate how Terraform stores sensitive data in plain text within the state file.
What to do instead: Use native data sources (AWS Secrets Manager, HashiCorp Vault) to fetch secrets at runtime. Mark all sensitive variables with sensitive = true. Never commit .tfvars files containing real credentials.
Ignoring Drift
What it looks like: Someone makes a “quick fix” in the AWS console during an incident. The next automated terraform apply detects the discrepancy and destroys the manual change, potentially causing a second outage.
Why it happens: Panicked incident response. Operational convenience. The cloud console is right there.
What to do instead: Run automated drift detection (a terraform plan on a cron job every 6 hours, alerting on discrepancies). At the advanced end, follow Cloudflare’s approach and make the console read-only.
Misusing count for Resource Iteration
What it looks like: You remove item 2 from a list of 5 resources managed with count. Terraform shifts all subsequent indices and destroys/recreates resources 3, 4, and 5. One of them is a production database.
Why it happens: count was the original iteration mechanism in older Terraform versions. Many engineers are unaware of for_each.
What to do instead: Always use for_each with a map or set of strings. Resource identifiers tie to immutable string keys instead of shifting numerical indices.
What You Can Do Next Week
Here is a concrete checklist, ordered by impact:
- Audit your execution model. If anyone on your team runs
terraform applyfrom a laptop against production, fix that first. Set up Atlantis, GitHub Actions, or HCP Terraform. Deny manual provisioning via IAM policies. - Measure your blast radius. Count the resources in your largest state file. If it is over 200, start planning a partition. Use the directory structure below as a reference:
terraform-monorepo/
├── modules/ # Reusable, zero provider config
│ ├── network/
│ │ ├── main.tf
│ │ ├── variables.tf
│ │ └── outputs.tf
│ └── compute/
├── live/ # Minimal code, env-specific .tfvars
│ ├── production/
│ │ └── us-east-1/
│ │ ├── terragrunt.hcl
│ │ └── main.tf
│ └── development/
- Add drift detection. Even a simple cron job running
terraform planand sending Slack alerts on discrepancies is better than nothing. Less than one-third of organizations continuously monitor for drift. - Implement Policy-as-Code. Start with 3-5 critical rules (no public S3 buckets, no unencrypted storage, mandatory tagging). Deploy them in advisory mode first.
- Use cross-account IAM with assume_role. Stop hardcoding credentials per environment:
# providers.tf
provider "aws" {
region = "us-east-1"
assume_role {
role_arn = "arn:aws:iam::111111111111:role/TerraformExecutionRole"
session_name = "terraform-ci"
external_id = var.external_id
}
max_retries = 25 # Critical for cross-account API throttling
}
- Replace
countwithfor_each. Grep your codebase forcount =on non-trivial resources. Migrate the stateful ones first.
The Uncomfortable Trade-offs
No honest discussion of Terraform at scale is complete without acknowledging where the popular advice breaks down.
The OpenTofu fork is real and growing. HashiCorp’s 2023 switch from MPL 2.0 to BSL 1.1 created genuine strategic risk for Managed Service Providers and platform companies. If you are building a product on top of Terraform, you need to evaluate this carefully. If you are using Terraform internally to deploy your own infrastructure, the license change likely does not affect you at all. But the community split means ecosystem fragmentation is a long-term concern.
Native Terraform workspaces (the terraform workspace new prod kind) are, in my experience, an operational trap. They use the same directory and same .tf files but silently switch the underlying state file. An engineer reviewing the Git repo cannot visually see what environments exist. There is no physical prod folder to inspect. This violates basic GitOps visibility principles and increases the risk of accidentally applying to the wrong environment. Use directory-based separation instead.
And then there is the “You’re Not Netflix” argument, which is valid. Netflix runs over 50,000 individual Terraform files and needs 100+ engineers just to maintain the IaC tooling. Applying that level of infrastructure complexity to a mid-sized application with modest traffic creates technical debt that will outlive the application itself. Right-size your Terraform architecture to your actual scale, not your aspirational scale.
Closing Thought
The Terraform AWS provider just crossed 5 billion downloads. The tool is not going anywhere. But the gap between “we use Terraform” and “we use Terraform well” is widening, not narrowing. The organizations that get this right treat infrastructure code with the exact same rigor as application code: strict modularity, automated testing, zero-trust execution, and continuous validation.
That 94% of companies still stuck in partial codification? They are not lacking a tool. They are lacking the operational discipline to use the tool they already have. The patterns in this post are not theoretical. They are what Cloudflare, Stripe, Uber, Benchling, Fannie Mae, and others built after learning the hard way.
The question is whether you will learn from their experience or repeat it.